
The Art of Building Tiny Language Model - Shrinking Intelligence
| By Abhishek Dey | June 21, 2026 | Level 400 | ORCID: 0009-0006-5427-7058 |
The Experiment
I am learning to fly Tiny Whoops, 65mm quadcopters that weigh less than 30 grams, rip through rooms at 40 km/h, and respond to stick inputs so fast that your reflexes are the bottleneck, not the machine. I picked up a Radiomaster controller to seize its control, building muscle memory through the simulator, where failure is free and repetition is the only path to precision.

this one is not my hand
The thing is, there’s no margin for error. One wrong throttle move and you’re in the wall. The reason it’s so difficult is that every control is extremely sensitive at this scale. Throttle, yaw, pitch, roll, all of them. Even a small change in thrust sends you into a wall or spins you out. So calibration matters a lot. If your controller isn’t set up properly, you’re spending all your time fighting the hardware instead of actually learning how to fly. That’s wasted effort. And here’s the thing: I am still in the simulator. The real flight is going to be harder because there’s battery sag that changes your thrust as the pack drains, prop wash bouncing off walls, furniture everywhere, and no reset button. If you haven’t gotten comfortable with the controls in the sim, that first real battery is going to last about 30 seconds and end with broken props. Now the same idea applies to language models. When we take a decoder model down to 10 million parameters or less, we can’t hide behind scale anymore. Every choice we make in the architecture shows up in the output. The number of layers, the embedding size, the vocabulary, all of it matters because there’s nothing else to compensate. At 7 billion parameters, a bad decision gets absorbed by everything else around it. At 10 million, it shows up right away. That’s why building tiny models is useful. We see what every part is doing, because there’s nowhere for mistakes to hide.
Tiny Models Under the Microscope
A tiny model is a neural network with less than 10 million parameters. To put that in context, frontier models typically contain tens to hundreds of billions of parameters, and even the smallest useful open models start around 1 billion. So when we say tiny, we mean 100 to 1000 times smaller than what people normally consider a language model. If we design it well, we can even train and inference a tiny model using just a CPU.
Within this blog, I will walk through my experiments on tiny decoder models. I trained four different sizes: 10M, 7M, 5M, and 2.5M parameters, all on the same dataset, and compared their performance against nine inference metrics (TTFT, TPS, total latency, tokens generated, perplexity, avg token probability, repetition rate, coherence length, and vocab diversity). I designed and architected these models using Jupyter Notebook, wrote the training code in PyTorch from scratch, trained a custom BPE tokenizer for each vocabulary size, and ran all experiments on a single GPU. The goal was to find out where the floor is: how small can a decoder model get before it stops producing anything useful, and what breaks first as you shrink it.
The Dataset and Tokenizer
I have chosen TinyStories as the dataset, available on HuggingFace at roneneldan/TinyStories. It contains 2.2 million short children’s stories, each between 50 and 200 words. Total size is approximately 470 million tokens. The stories use simple vocabulary, short sentences, and basic narrative structure.
Dataset specifications:
Name: TinyStories
Documents: ~2.2 million stories
Avg length: ~200 tokens per story
Total tokens: ~470M
Language: English
Vocabulary: Simple (children's level, ~5000 unique words)
Format: Plain text, one story per entry
For the tokenizer, I trained a custom BPE (Byte Pair Encoding) tokenizer for each model size using the tokenizers library. BPE works by starting with individual characters, then iteratively merging the most frequent pairs into single tokens until the target vocabulary size is reached. The output is a single JSON file:
tinystories_tokenizer.json — contains vocabulary, merge rules, and config in one file
Library: HuggingFace tokenizers (BpeTrainer)
Special tokens: <pad>, <eos>, <bos>, <unk>
For tiny models, vocabulary size is the most critical decision:
Vocab too large (32000 for a 5M model):
Embedding table = 32000 × 256 = 8.2M params
Remaining budget for layers = 1.8M
Result: 1 layer, can't learn anything useful
This is overfitting the vocabulary to a model that can't support it
Vocab too small (256 bytes for a 5M model):
Embedding table = 256 × 256 = 65K params
Remaining budget for layers = 4.9M
Result: good layer budget, but each word needs 5-7 tokens
Sequences become very long, context window fills fast
Model generates character by character, slow and fragmented
Vocab right-sized (1000 for a 5M model):
Embedding table = 1000 × 256 = 256K params
Remaining budget for layers = 5M
Result: 4 layers with full capacity, 1-2 tokens per word
Best balance between budget allocation and sequence efficiency
The rule: the embedding table should consume no more than 5-10% of your total parameter budget. If it takes more, the model is starved for computation layers. If it takes less, your sequences are unnecessarily long and the context window fills up before the model can say anything useful.
Model Architecture
I tested four decoder-only transformer models to build Tiny LM, all sharing the same structure but at different scales. The architecture is standard: token embeddings, positional embeddings, stacked transformer blocks (attention + FFN + residual + RMSNorm), and a final output head tied to the embedding weights.
# 5M Model Config
vocab_size = 1000
dim = 384
n_layers = 2
n_heads = 4
ffn_dim = 1536
max_seq_len = 256
tie_weights = True
total_params = 5_000_000
Here are the four configs:
Table 1: Model Configurations
| 10M | 7M | 5M | 2.5M | |
|---|---|---|---|---|
| Parameters | 10.7M | 6.9M | 5.0M | 2.5M |
| Vocabulary Size | 2,000 | 1,500 | 1,000 | 512 |
| Embedding Dim (d) | 384 | 224 | 384 | 272 |
| Layers (L) | 4 | 8 | 2 | 2 |
| Attention Heads (H) | 4 | 4 | 4 | 4 |
| FFN Dim (4d) | 1,536 | 896 | 1,536 | 1,088 |
| Context Length | 256 | 256 | 256 | 256 |
| Head Dim (d/H) | 96 | 56 | 96 | 68 |
When you shrink a model, you can’t just reduce one thing. Everything has to come down together. The vocab shrinks because the embedding table is a matrix of size vocab × dim, and if vocab is too large it dominates the parameter count, leaving nothing for the actual computation. The dimension shrinks because every weight matrix in the model is proportional to dim², so even small reductions in dim save a lot. Fewer layers because each layer needs to be wide enough to do something, a very narrow layer is useless regardless of how many you stack. And heads track dim at 64 per head, below that they can’t learn distinct attention patterns.
The FFN stays at 4× dim across all configs. This ratio comes from the original transformer and still works at small scale. Context length is 256 for the top three models and 128 for the 2.5M. At 2.5M the model loses coherence around 50 tokens regardless, so the extra positions just waste parameters on something the model will never use.
Parameter budget for the 5M model:
Token embeddings: 1000 × 256 = 256K
Position embeddings: 256 × 256 = 65K
Per layer (×4): (4×256² + 2×256×1024 + norms) × 4 = ~4.2M
Output head: tied with embeddings = 0
Total: ~5.3M
The Training Run
I designed the training loop in PyTorch and Python 3.12, prototyped in Jupyter Notebook, and ran the final training via tmux on a single NVIDIA L4 GPU (24GB VRAM). The optimizer is AdamW with betas (0.9, 0.95) and weight decay 0.01, following the configuration used in most modern small-scale LLM experiments.
Each training step does three things: forward pass, loss computation, backward pass. A batch of 64 sequences enters the model. For the 5M config, each sequence passes through 4 transformer blocks sequentially:
→ RMSNorm → Attention → residual → RMSNorm → FFN → residual
Four times. The output head produces logits over the vocabulary at every position, and cross-entropy loss measures how far off the predictions are from the actual next tokens.
Backpropagation then computes the gradient of that loss with respect to every parameter in the network.
optimizer = "AdamW"
learning_rate = 3e-4 # standard for small transformers
lr_schedule = "cosine decay" # anneals to zero over training
batch_size = 64 # gradient averaged over 64 sequences
training_steps = 50_000
warmup_steps = 500 # linear warmup, avoids early divergence
weight_decay = 0.01 # L2 regularization
gradient_clipping = 1.0 # stabilizes training at small scale
precision = "float32"
hardware = "single GPU"
dataset = "TinyStories"
I ran 50K steps for all four model training. Loss converges between 30-40K steps and plateaus after that. At this point the model has saturated its representational capacity. Additional steps lead to memorization of frequent patterns rather than generalization. The learning rate schedule is important here: cosine decay lets the model make large corrections early when the loss landscape is steep, and fine-grained adjustments late when it’s navigating a flatter region near the minimum.
The Complete Training Pipeline in Action: Building a 5M Parameter Model from Scratch
Model Repository
I have published all pre-trained models on HuggingFace, model location = deycoding/deycoding-tiny-language-model. (Model size = 10M, 7M, 5M, 2.5M)
The repository contains PyTorch model weights (.pt files) for all four sizes (10M, 7M, 5M, 2.5M), their corresponding BPE tokenizer files (.json), and a config file with the architecture parameters. Load any model by rebuilding the architecture from the config and calling model.load_state_dict(torch.load('file.pt')). Each tokenizer is self-contained with vocabulary, merge rules, and special tokens. No external dependencies needed for inference.
Model Serving:
import torch
from tokenizers import Tokenizer
# Load
tokenizer = Tokenizer.from_file("tinystories_10m_tokenizer.json")
model = LLM(ModelConfig()).cuda()
model.load_state_dict(torch.load("tinystories_10m_final_model.pt"))
model.eval()
Results and Benchmarks
I generated 100 samples from each of the four models (400 total) using identical TinyStories-style prompts: story openings, character introductions, action prompts, and dialogue starters. All generation used temperature 0.8, top-k 50, max 256 tokens. For each sample, I captured 9 metrics during inference and averaged them across 100 outputs per model. The results show that automated metrics measure token-level patterns, not semantic quality.
2.5M scores best on nearly every automated metric: fastest inference (538 TPS), lowest repetition (6.8%), longest coherence (27.3 tokens), highest diversity (83.7%), highest token probability (0.538). But it produces the worst actual quality. It generates the most tokens (37.1 avg) because it rarely hits meaningful EOS, just keeps going. The coherence metric misses semantic nonsense like “The pool is so deep that there are many water in the water.” The model produces high-confidence incorrect output.
10M produces the best output quality despite the worst automated scores. Fewest tokens (26.7 avg) because it stops at natural boundaries. Highest repetition (13.0%) because in shorter outputs one repeated phrase registers as a higher percentage. But the text has cause-effect, natural dialogue, and story structure.
7M is the slowest (169 TPS vs 297-538 for others) because 8 layers at dim=224 creates sequential bottleneck. Despite extra depth, quality is worse than 10M and 5M. It misuses words (“fragile” for weather, “passport” for a king) because 56 dims per attention head is too narrow for proper semantic representation. Width matters more than depth at this scale.
5M (2 layers, dim=384) produces clean, grammatically correct, short outputs. Stops early rather than degrading. Low repetition (9.5%), high diversity (83.5%). But only 2 layers means limited multi-sentence coherence. Precise but limited.
Table 2: Performance Benchmarks
Benchmarks produced by running the benchmarking scripts on top of the model serving evaluation results.
| # | Metric | 10M | 7M | 5M | 2.5M |
|---|---|---|---|---|---|
| 1 | TTFT (ms) | 5.5 | 7.8 | 4.1 | 4.1 |
| 2 | TPS (tokens/sec) | 297 | 169 | 531 | 538 |
| 3 | Total Latency (ms) | 90.2 | 178.5 | 61.0 | 68.7 |
| 4 | Tokens Generated (avg) | 26.7 | 30.3 | 32.2 | 37.1 |
| 5 | Perplexity | 4.1 | 3.8 | 4.3 | 3.8 |
| 6 | Avg Token Probability | 0.496 | 0.513 | 0.494 | 0.538 |
| 7 | Repetition Rate | 13.0% | 12.2% | 9.5% | 6.8% |
| 8 | Coherence Length | 21.7 | 23.2 | 22.4 | 27.3 |
| 9 | Vocab Diversity | 82.3% | 81.2% | 83.5% | 83.7% |
TTFT = Time to generate the first token after prompt. Lower = faster response.
TPS = How many tokens the model generates per second. Higher = faster.
Total Latency = End-to-end time for full output. Lower = faster completion.
Tokens Generated = Average output length before hitting EOS or max limit.
Perplexity = How surprised the model is by its own output. Lower = more confident.
Avg Token Probability = Average confidence per token chosen. Higher = more certain.
Repetition Rate = % of tokens that repeat within a 10-token window. Lower = less looping.
Coherence Length = Tokens generated before first 3-gram repetition. Higher = longer coherent span.
Vocab Diversity = % of unique tokens in the output. Higher = more varied vocabulary usage.
Plots generated using benchmarking scripts from 400 data points across four models.
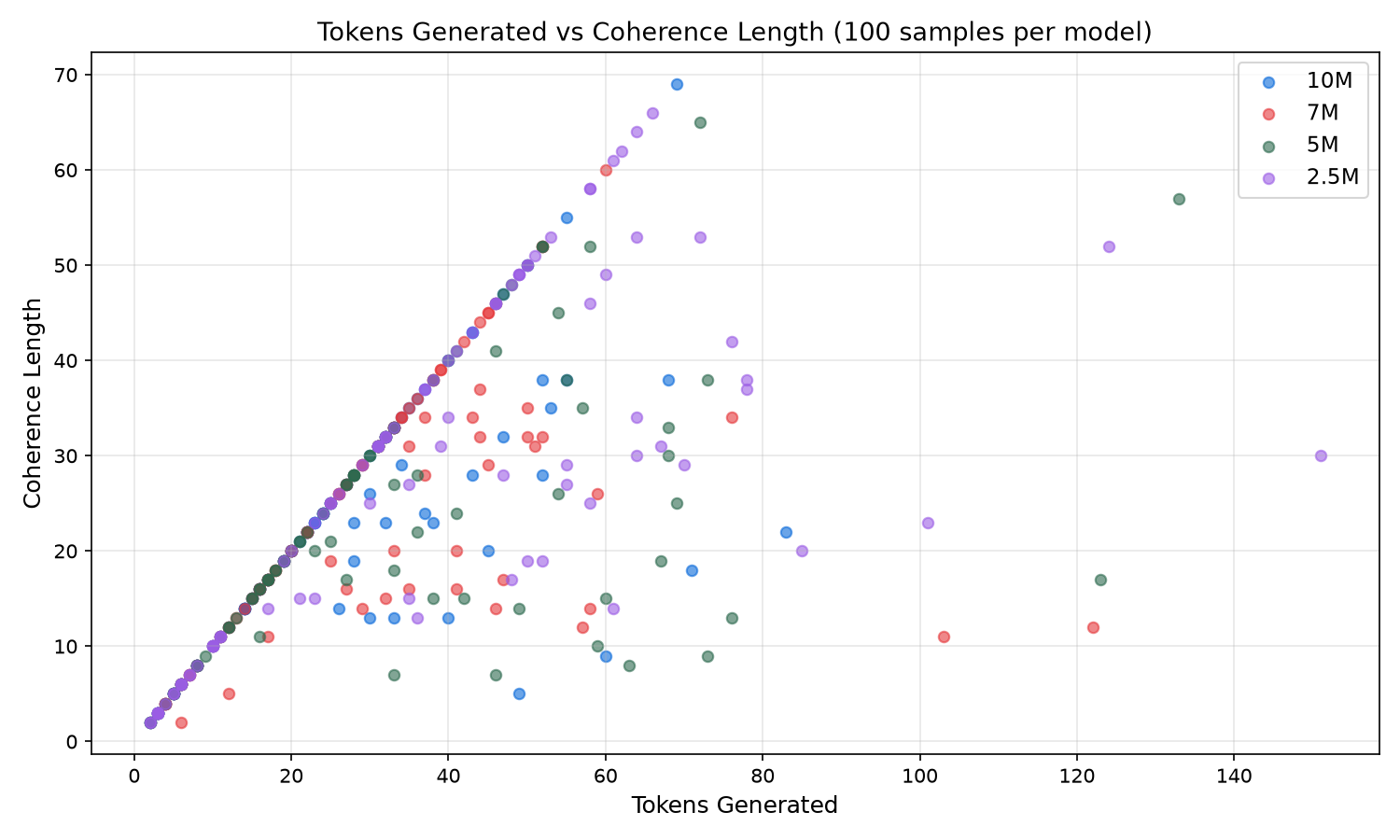
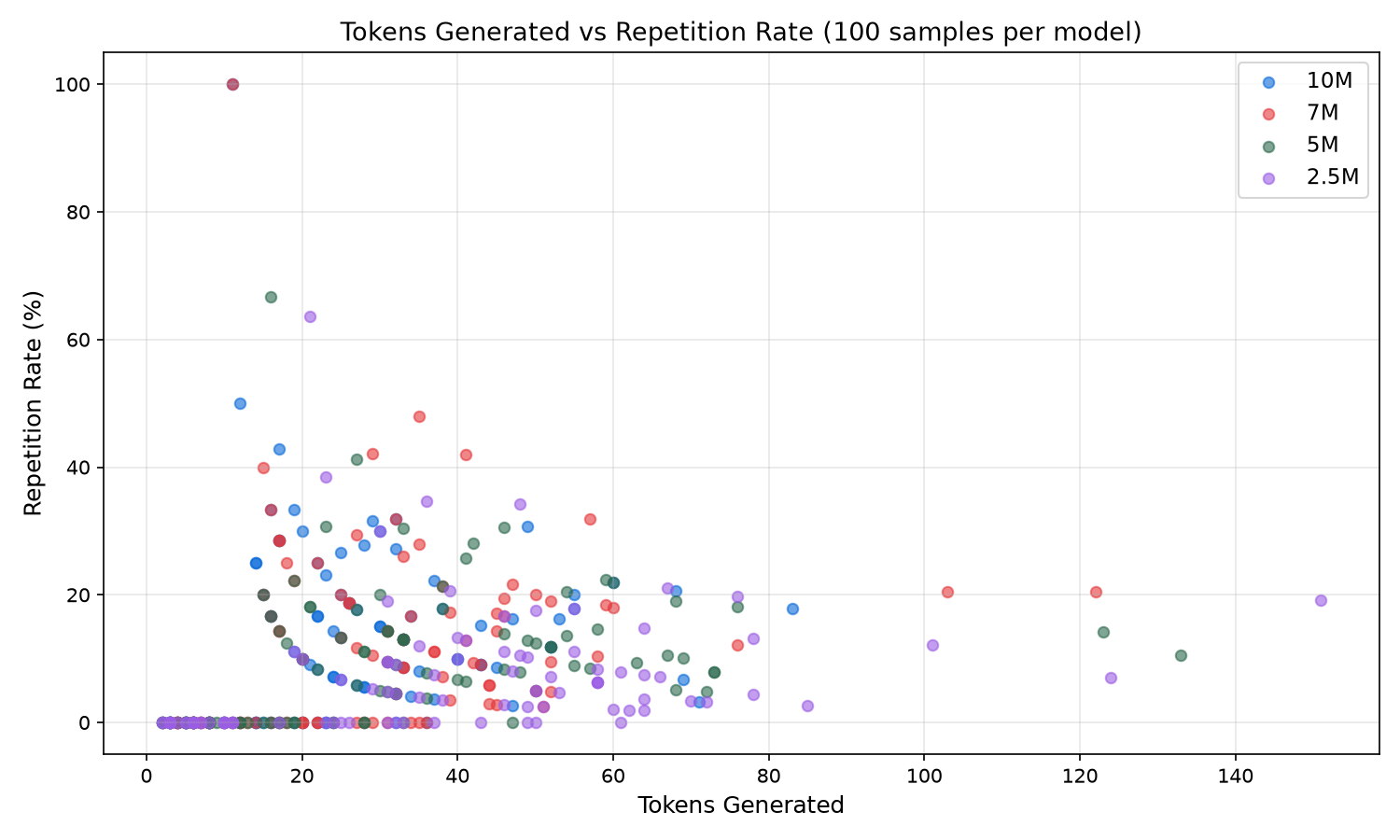
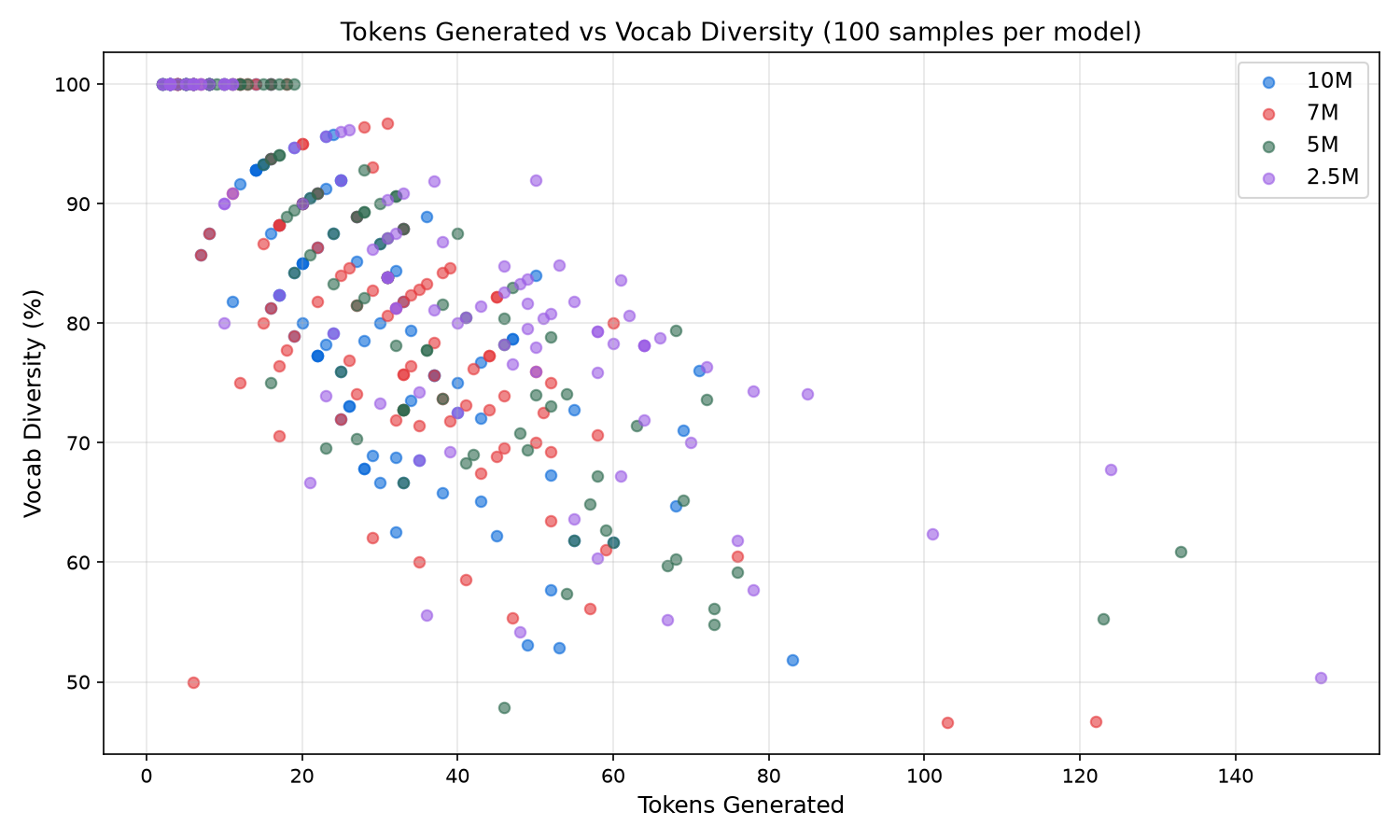
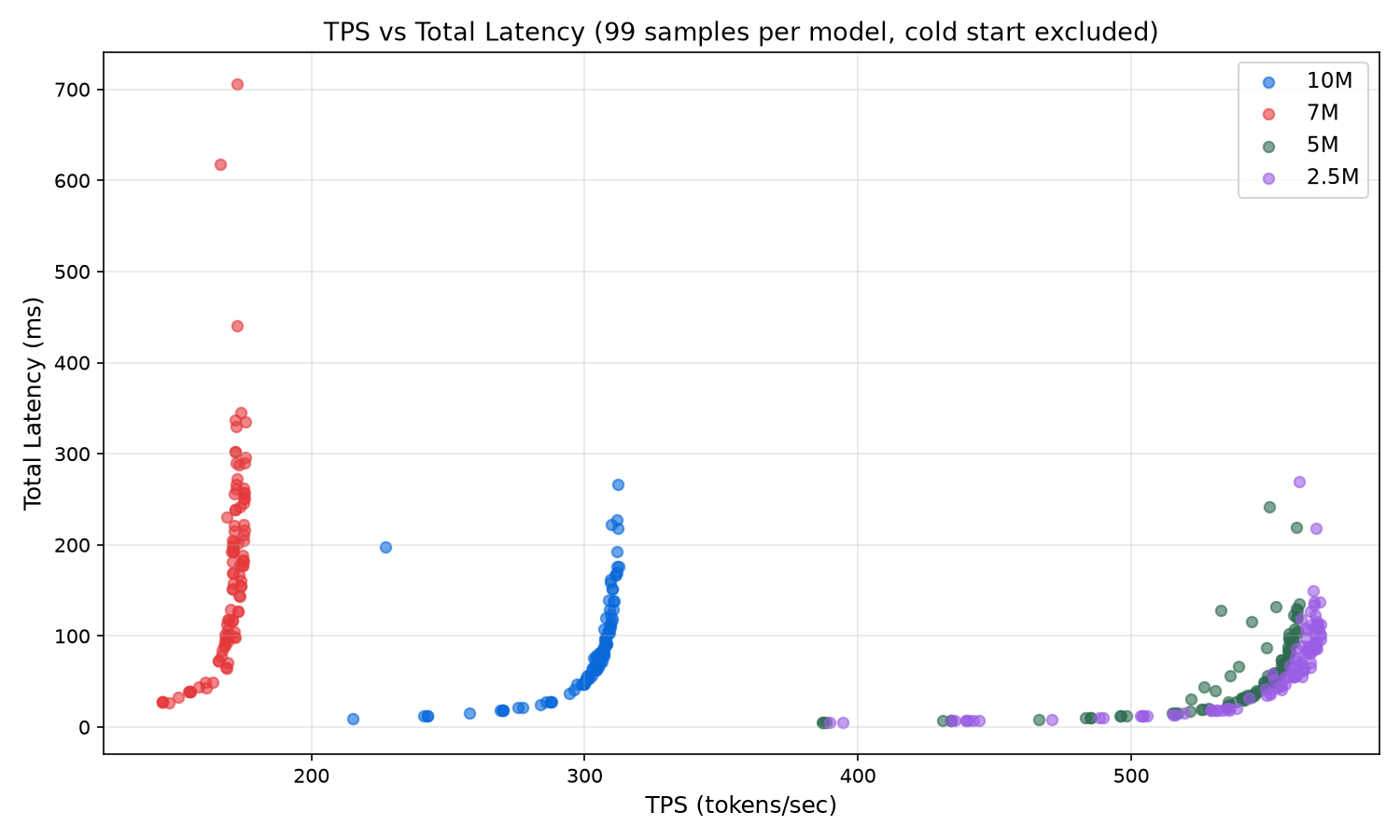
Explanation = The plots above visualize 400 individual data points across four models. The tokens-vs-coherence plot shows that 10M clusters tight near the diagonal at shorter lengths, meaning it stays coherent for nearly its entire output, while 2.5M scatters wide with high token counts but coherence breaking early. The tokens-vs-repetition plot reveals the quality cliff: short outputs cluster at 0% repetition across all models, but as token count increases, 10M stays below 20% even at 50+ tokens while 7M shows scattered high repetition outliers at 100+ tokens. The tokens-vs-diversity plot shows vocabulary exhaustion as output grows, with 7M dropping fastest due to its smaller vocabulary and mode collapse forcing early token reuse, while 5M and 2.5M maintain 70-80% diversity even at longer outputs. The TPS-vs-latency plot makes the architectural penalty visible: 5M and 2.5M cluster at 500 to 560 TPS with sub-100ms latency, 10M sits at 300 TPS mid-range, and 7M forms a distinct slow cluster at 165 to 175 TPS with latency stretching to 600ms+ because 8 sequential layers double the compute per token.
Raw metrics and sample outputs are available at deycoding/deycoding-tiny-language-model/benchmarking, plotting scripts at deycoding/deycoding-tiny-language-model/benchmarking-scripts.
What Broke and Why
All four models learned to generate grammatically correct English from scratch with less than 10 million parameters. They produce subject-verb agreement, proper punctuation (even professionals and corporate leaders routinely misplace commas and full stops in Slacks and emails despite years of education, yet a model with less than 10 million parameters places them correctly in every output), sentence structure, and natural-sounding dialogue. The 10M model generates coherent short stories with characters, actions, and endings. The 5M model produces clean, well-formed sentences. Even the 2.5M model produces outputs like “His mommy came in and saw what happened. She hugged Timmy and told him not to worry” which is grammatically correct, emotionally appropriate, and contextually relevant.
What broke is not grammar but meaning at scale.
The 7M model generates fluent text that is semantically wrong (“He wanted to play outside, but it was fragile.” “The king loved his ordinary passport.”) because at dim=224 with 56 dimensions per attention head, the model learns where words go but not what they mean. The 2.5M model has not learned when to stop, generating 37 tokens on average compared to 27 for 10M, not because it has more to say but because it has not learned EOS boundaries, and past 20 tokens grammar holds but meaning dissolves (“The pool is so deep that there are many water in the water.”). The 10M model breaks past 40 to 50 tokens where the hidden state at dim=384 runs out of capacity to track what was already said and repetition begins, but within that range it produces structured narratives with cause and effect. The 5M model does not break, it simply stops, two layers produce clean fragments but cannot build multi-sentence narratives. None produce proper nouns or multi-step reasoning, those capabilities need parameter budgets beyond what any of these architectures can provide.
Conclusion
In Tiny Whoop flying, the small frame and the tight room leave no room to be sloppy. You either fly precise or you hit the wall. Same with tiny models. At 5-10M parameters, every architectural decision is visible in the output.
Two findings stood out. First, width matters more than depth. The 5M model (2 layers, dim=384) produces better output than the 7M model (8 layers, dim=224) despite having fewer parameters. Second, automated metrics do not measure quality. The 2.5M model scores best on repetition, coherence, and diversity metrics, yet produces the worst actual text.
In the age of LLMs where we talk about 70 billion and 400 billion parameters, I did not expect that a 2.5M parameter model could even barely generate anything. But it does. All four models learned grammar, punctuation, and sentence structure from scratch in under an hour of training. What does not emerge below 10M is semantic precision, knowing when to stop, and multi-sentence reasoning.
I built these models to understand how transformers work at the component level. At this scale, you train a full experiment in under an hour and develop real intuition for what each architectural choice does. And practically, if you fine-tune a 10M model on a narrow task with short context and few output tokens, it runs on a CPU in under 1 millisecond, no GPU, no API, no internet. For tiny language model use cases, the model does not need to know everything. It just needs to know one thing very well.
And here you Go….
© 2026 Abhishek Dey (ORCID: 0009-0006-5427-7058). Content licensed under CC-BY-NC-4.0.