
What Does 70B Parameters Actually Mean?
| By Abhishek Dey | June 15, 2026 | ORCID: 0009-0006-5427-7058 |
The Question
I have chosen 70B randomly for the title - however, the reason for this neural resonance is that it sits right where the real tradeoff conversation lives: big enough to reason, small enough to actually serve.

I recently trained a decoder dense 3B parameter model (not MoE, MoE was 1B what I trained) from scratch on an NVIDIA L4 24GB. It took approximately 300 hours to pre-train from scratch with frequent checkpoints every 5000 steps - and by “from scratch” I mean designing the neural network architecture, writing the training loop, and building the model from nothing, not fine-tuning on top of an existing model. What I usually build from scratch, the industry calls a sovereign model. Then the question occurred to me - as an individual, what patience and infrastructure would I need to train a 7B and then a 70B parameter model? Do I really need a 70B parameter model?
People talk about parameters, flex the model size they use and they talk about tokens as if the numbers alone tell the full story - “70B is better than 7B,” “we need a larger model,” “bigger is always better.” Most data scientists and engineers reach for the biggest model available without truly understanding what those 70 billion parameters actually represent, where the number comes from, or what each component contributes to the model’s capability - assuming that bigger will solve every problem, that it eliminates the need for benchmarking and baselining, and that it guarantees a faster go-to-market. The number 70B isn’t magic - it’s just what falls out when you pick a certain depth, width, and FFN size. If you can’t explain why your problem needs 70B instead of 7B, you’re paying 100× more for vibes, burning GPU hours that could fund three smaller experiments, shipping slower because inference latency kills your user experience, and locking yourself into infrastructure that only scales with money, not with insight. Let’s break that number open and see what’s actually inside.
What 70B Parameters Means
A 70B parameter model means there are 70 billion individual numbers (weights) stored across all the matrices in the network. Here network means Neural Network (NN) - however for me, “network” also marks a personal pivot from computer networks to neural networks as an independent researcher. But let’s get back to the math. This number comes directly from the architecture choices: the embedding layer (vocabulary size x dimension), each transformer layer’s attention matrices (Q, K, V, output projections) and feed-forward network matrices (two or three large linear layers), repeated across all layers, plus the final output projection. For example, if you set dimension to 8192, use 80 layers, and have an FFN that expands to 28672 - the attention matrices in each layer contribute roughly 4 x 8192 x 8192 = 268M parameters, the FFN contributes roughly 3 x 8192 x 28672 = 704M parameters, multiply by 80 layers and add the embedding - you land at approximately 70 billion. The “70B” is not a target you aim for arbitrarily; it falls out of choosing a specific depth (layers), width (dimension), and expansion ratio (FFN size) that together give the model enough capacity to store the patterns from trillions of tokens of training data. Being a science student, I always believe in simplifying the math concepts and logic - therefore don’t worry, I will explain this maths in the next section in the best possible way and remaining is your study.
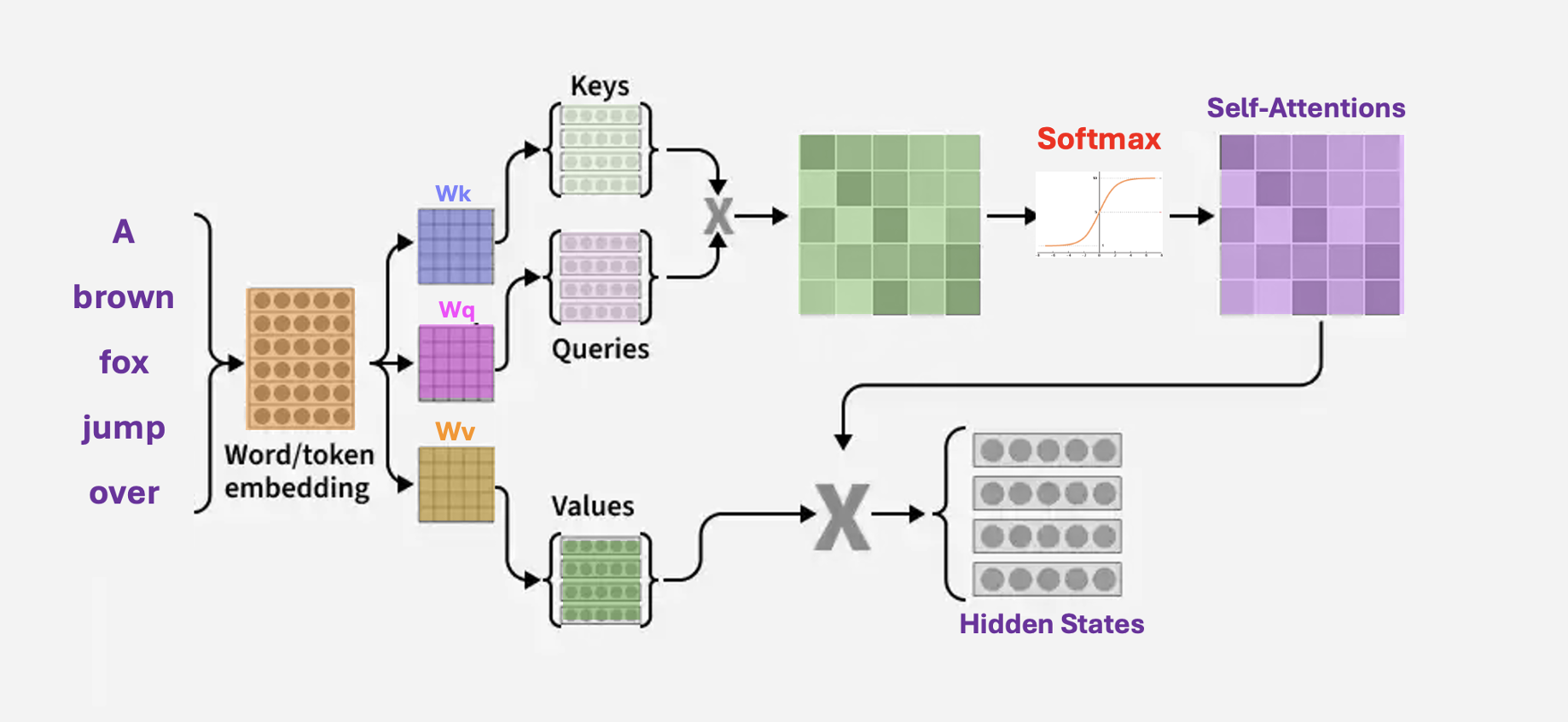
Self attention architecture
The Size Illusion: What People Infer from Model Size
Bigger is generally better - but only up to a point, and the gains shrink fast as you scale. Going from 3B to 70B is a real difference you can feel - the model moves from basic instruction following to genuine multi-step reasoning, strong code generation, and nuanced understanding of complex topics. Going from 70B to 380B? The improvement shows on benchmarks, but in everyday use a typical user would struggle to tell the difference. You get marginally less hallucination, marginally better performance on rare languages and the hardest tasks - but nothing close to the leap from 3B to 70B. The cost and infrastructure required, however, scales aggressively with every jump in size.
What people take away from these numbers: 3B means “good enough for a specific task, runs on a single L4 24GB.” 70B means “serious production model, needs dedicated GPU infrastructure.” 380B means “frontier research, accessible only to well-resourced labs.” But the number only signals capacity ceiling - not guaranteed quality. A well-trained 7B model with carefully curated data can outperform a poorly trained 70B model on specific tasks. Size gives you room to store knowledge and patterns, but data quality and training technique decide how much of that room actually gets used well.
The Formula
P = P_embedding + L x (P_attention + P_ffn + P_norms) + P_output
Full formula (SwiGLU, no weight tying):
P = 2Vd + L x (4d² + 3d x d_ff + 2d)
Example (Llama 70B): d=8192, L=80, V=32000, d_ff=28672
P = 2 x 32000 x 8192 + 80 x (4 x 8192² + 3 x 8192 x 28672 + 2 x 8192)
P ~ 524M + 80 x (268M + 704M + 16K)
P ~ 524M + 77.8B
P ~ 70B
Inside the Architecture: Where Algebra and Calculus Play Out
P_embedding = V x d: Converts tokens into vectors. A lookup table where each row is a word’s meaning as d numbers. This is where language enters the model.
P_attention = 4 x d²: Four matrices (W_Q, W_K, W_V, W_O) that let tokens look at each other and decide what’s relevant. This is where relationships between words are learned.
P_ffn = 3 x d x d_ff: Three matrices (gate, up, down) that store factual knowledge. Holds ~70% of all parameters. This is where “Paris is the capital of France” lives as weight patterns.
P_norms = 2 x d per layer: Keeps numbers stable between layers. Tiny in count but without it, deep networks cannot train at all.
L = number of layers: Each layer is one cycle of attention + FFN. More layers = more “thinking steps.” Depth determines reasoning complexity.
V = vocabulary size: How many unique tokens the model recognizes. Too small = slow (many tokens per word), too large = wasted parameters on rare tokens.
d = model dimension: Width of every vector flowing through the network. The single most impactful choice. Double d and parameter count roughly quadruples.
d_ff = FFN intermediate dimension: Temporary expansion workspace (3.5-4x of d). Wider = more room to compute and store knowledge.
P_output = d x V: Final layer converting internal representation into next-token probabilities. Often shares weights with embedding (adds zero extra parameters).
Big Models (70B+): The Muscle
Big models handle ambiguity and nuance well - they understand context, sarcasm, and implicit meaning that smaller models take literally. They can chain 5-10 logical steps without losing track, making them strong at multi-step reasoning and complex problem solving. They have enough capacity to remember obscure and niche knowledge, be fluent in 20+ languages simultaneously without sacrificing quality in any one, and handle diverse tasks from code to creative writing to mathematical proofs within a single model.

But that power comes at a cost. Training from scratch runs $2-10 million - only well-funded labs can afford it. Serving requires multi-GPU setups costing $5-15K per month per deployment. Inference is slow at 50-100ms per token, which creates noticeable latency for users. Most critically, using 70B to answer simple questions is like driving a truck to buy milk - the vast majority of real-world queries don’t need that much capacity. And iteration is painful - each experiment takes weeks and costs millions, making rapid prototyping impossible.
Small Models (1B-7B): The Precision Tool
Small models are cost-efficient to train, fast at inference (5-15ms per token), and can run on a single GPU or even a mobile phone when quantized. They’re easy to iterate on - train, evaluate, retrain in hours rather than months. When fine-tuned on domain-specific data, they can match or outperform big models on that particular task, making them ideal as specialist tools rather than general-purpose assistants. The tradeoff is capability ceiling. Small models lose track after 2-3 logical steps, take things literally and miss nuance, and forget old knowledge faster when learning new things. They work best as single-task specialists - excellent at one domain but mediocre at everything else. They also demand more careful data curation because every training example has proportionally more impact on the final model.
Who Should Train What
If you are an individual or small team solving a specific problem - classification, routing, domain Q&A - with a budget under $5K and need real-time latency, train small (1B-3B). You’ll own the model, iterate fast, and deploy cheaply. If you are a startup building a product that needs general capability but domain-adapted, fine-tune a medium model (7B-13B) using LoRA on existing open weights - no need to train from scratch. If you are a well-funded lab with $10M+ budget, a team of 10+ ML engineers, 64+ GPUs, and need frontier performance across diverse tasks for a general-purpose product like a chatbot or coding copilot - then and only then does training 70B+ make sense.

Flexing Muscles with Big Models
The reality is that most companies announcing “we trained a 70B model” or “we use a 70B model” didn’t need to. They jumped on the bandwagon because bigger signals technical capability to various stakeholders. A well-trained 7B model with domain-specific data would have served their product just as well at significantly lower cost. For infrastructure, you can host the model on Amazon Bedrock, which solves your infra problem. The model size arms race is a mix of engineering and marketing. The real skill is to be frugal and sustainable - to train or identify a model that fits your need and serves your use case, rather than flexing model muscle.
Conclusion
The number of parameters in a model is not a scoreboard - it’s an engineering decision with consequences. Knowing that a model has 70 billion parameters should immediately tell you what infrastructure it demands, what it costs to run per query, and what class of problems justifies that expense. The real skill is not in accessing the biggest model - it’s in understanding exactly why a 3B model trained on the right data, served at 5ms latency for $30/month, can outperform a 70B model costing $15K/month for a specific task. Those who train large models do so because their problem genuinely requires that capacity - general-purpose reasoning, multilingual fluency, complex multi-step analysis. Those who train small models do so because they’ve identified the precise boundary where more parameters stop adding value for their use case. Both are valid. The difference between a good engineer and a great one is knowing which side of that boundary your problem sits on. Know your parameters. Know your tradeoffs. The best choice isn’t the most popular one - it’s the one that fits your purpose, values, and journey.
